
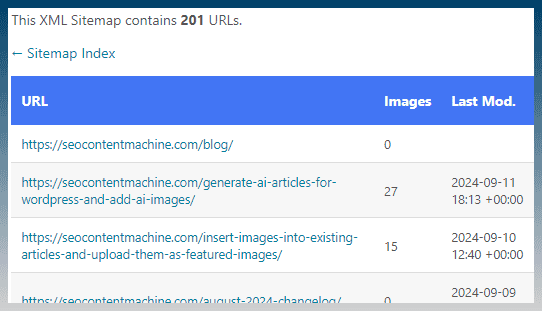
For easier indexing reasons most sites publish a sitemap xml.
This file is an easy way to get a list of all posts on a website.
We can use this file to download content to our hard drive.
Sitemap xmls look like this eg:
https://seocontentmachine.com/post-sitemap1.xml
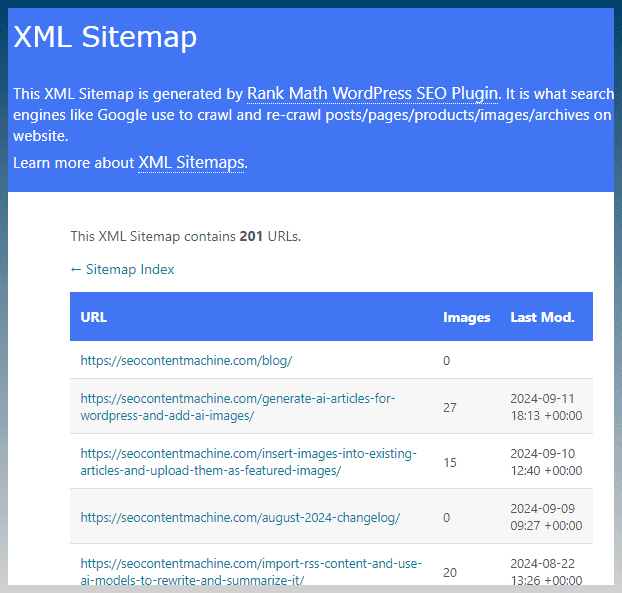
As you can see on our site, it lists all the posts.
To download this content inside SEO Content Machine, use the XML Scraper Tool.
XML Scraper Tool
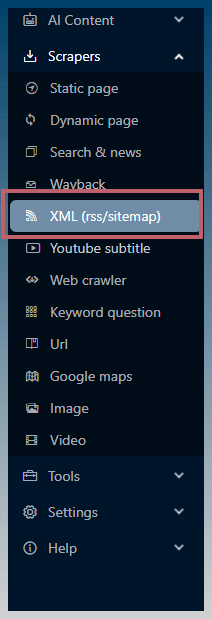
Find the tool under scrapers.
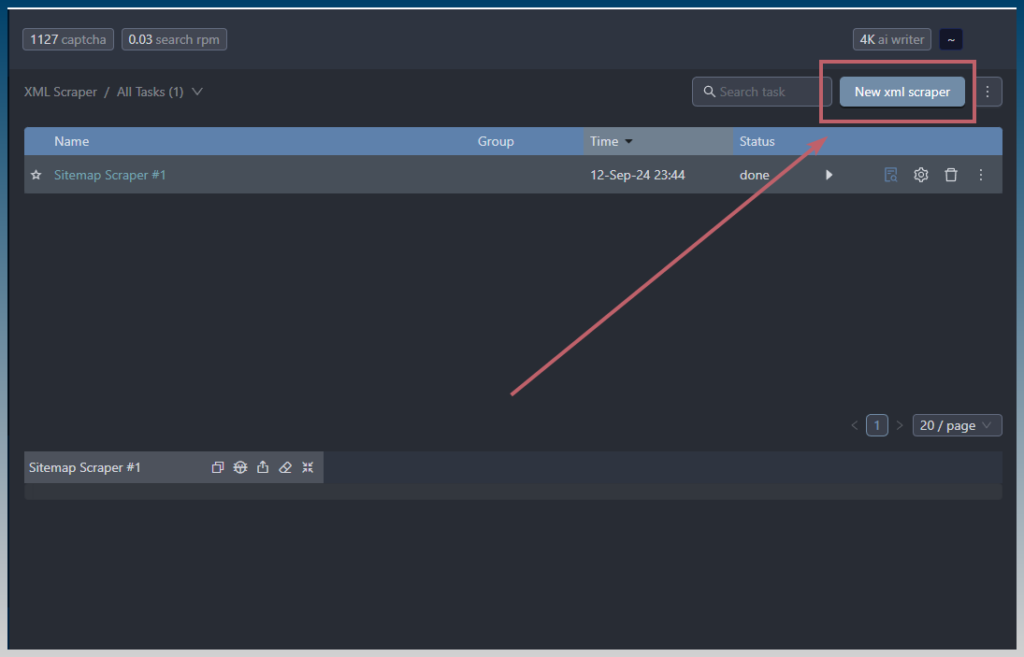
Create a new XML scraper task.
Paste in the sitemap xmls.

You can paste in multiple different sitemaps, one per line.
Check the default settings.
Selecting content
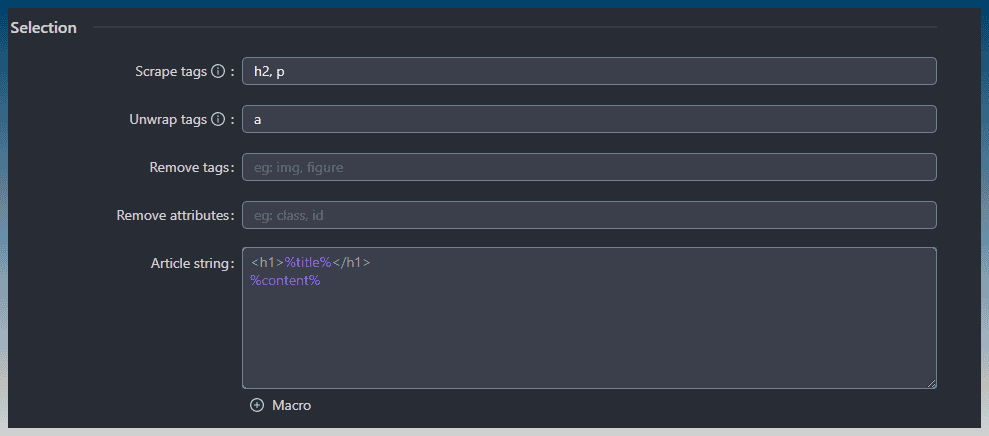
The scraper will download content using CSS selection.
The default is to download content inside H2 and P tags.
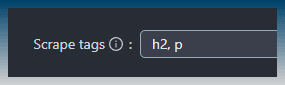
This is a comma separated list, you can add extra tags like H3, H4, DIV etc.
It will also unwrap any links so they are converted just to text.
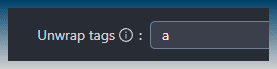
You can also remove tags and attributes.
Finally, you can shape the output of the saved content via the article string.
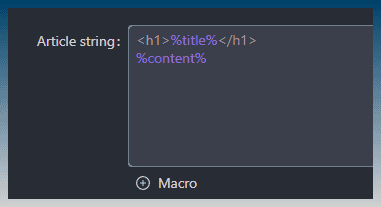
The tool will create an article on your hard drive with a H1 tag and the content of the article below it.
The title of the article is automatically detected by the tool and provided to you via the %title% macro.
The %content% macro is the scraped content from the scrape tags property. eg: H2, P tags
Filtering
You can manipulate the downloaded content.
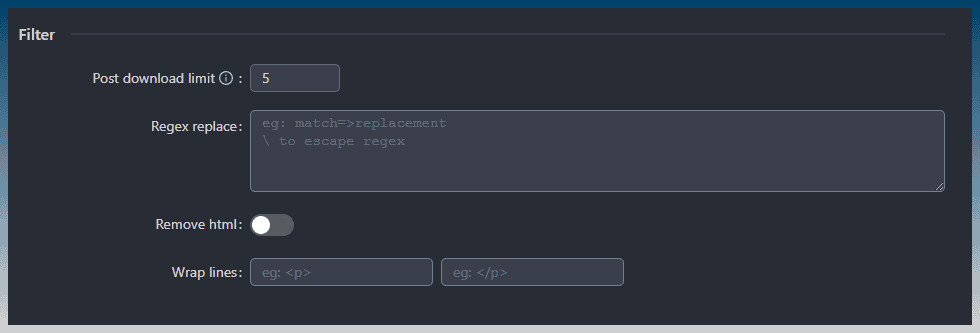
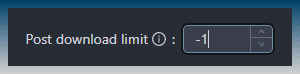
The first is to limit the number of items downloaded from the sitemap.
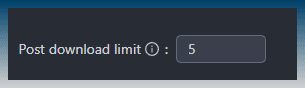
The default is 5.
There are tooltips as well!
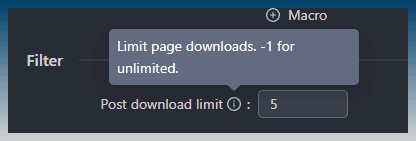
You can set the value to -1, to make the task download everything it can find.
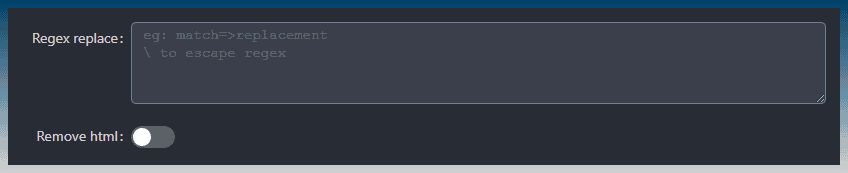
You can use regex to find and replace text content.
There is also a toggle to remove all HTML if you need a plain text article.
You can re-wrap all lines in another set of tags.

Rewriter
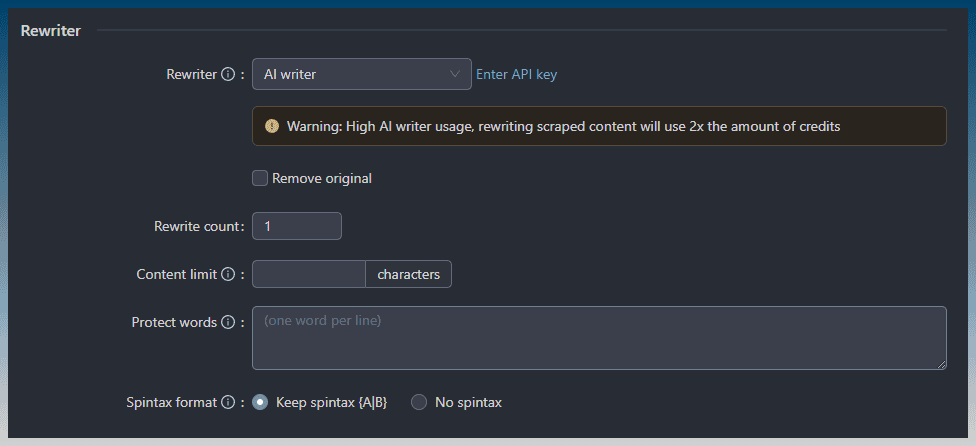
You can use a rewriter on scraped content to make it unique.
This means you can use AI as well.
Run it
Click run to start the task.
Output
Once the task starts running, click on its row to see a task log.
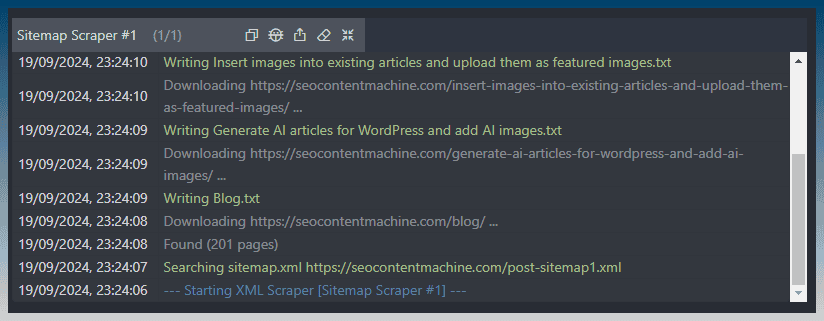
Posts are found from the sitemap and downloaded to your hard drive.