
If you just use a keyword tool to generate a list of keywords, its hard to use that list as is; unless you group them into related keywords first.
One of the easiest ways to group keywords together, is to use word embeddings and a clustering system to group semantically related keywords into topic groups.
I don't explain everything about what is being used below in fine detail, so you should know before hand what the following are:
- Word embeddings
- HDBSCAN (epsilon, min points)
- Cosine Simularity
The goal of my topic clustering system was to take a large keyword list eg 500 keywords, and group them into SEO optimized topic clusters.
Below I cover all the problems I had along the way to get topic clustering working.
The Real Problem with Keyword Clustering in SEO
The biggest problem I had once I figured out the basics of grabbing word embeddings from OpenAI and clustering via DBSCAN was… what numbers to use for epsilon.
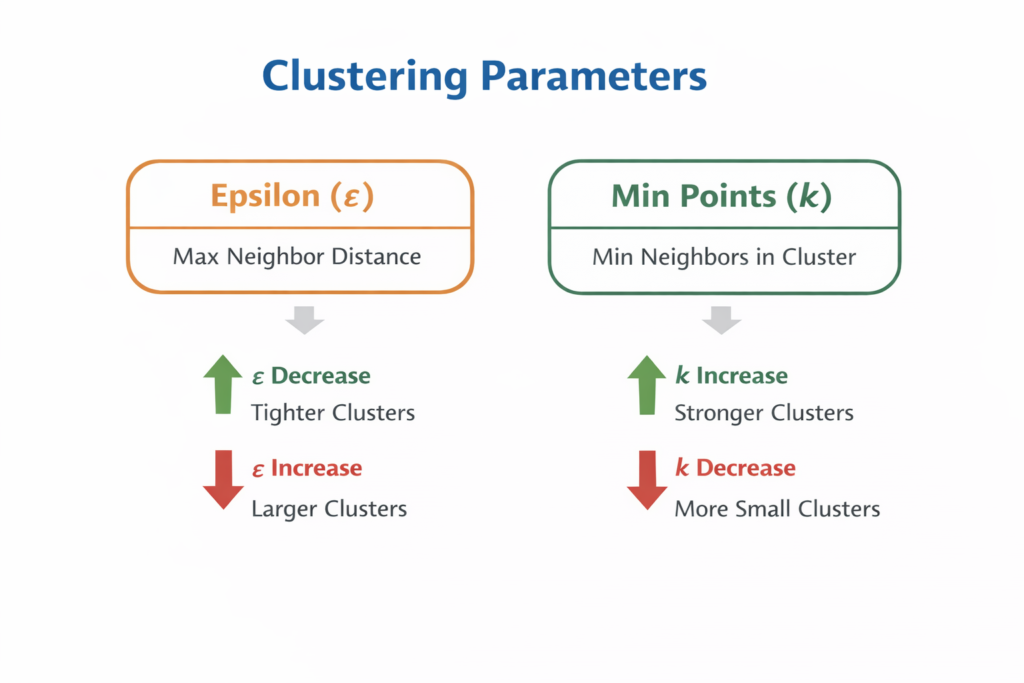
Initially I used a fixed epsilon of 0.15-0.35 and played around the numbers to see what would happen.
Going too low would create lots of 1 topic clusters, ie noise and going too high would create giant clusters of 100+ topics in one cluster.
Ie mega clusters!
The goal is to get around 3-8 topics per cluster.
I will be using seed keyword ‘elden ring'.
This is a good seed keyword because it demonstrates clearly the problem with brand text causing problems with clustering.
Here is a good example of epsilon 0.20 causing a mega cluster.
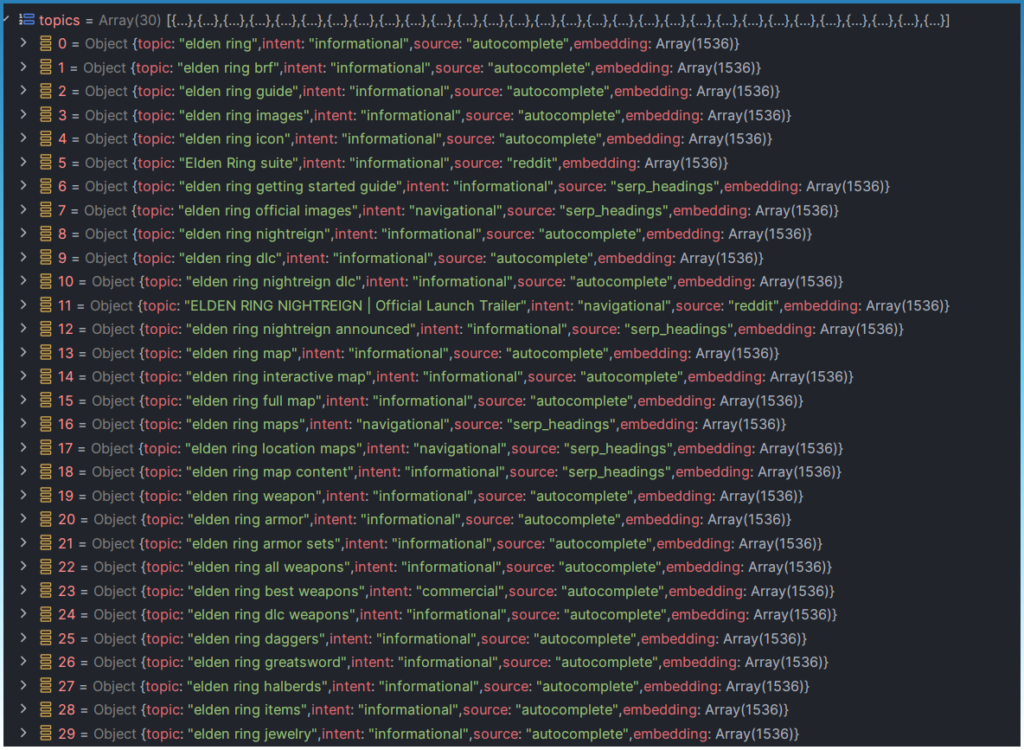
The problem here is that all the topics have the same starting shared keyword ‘elden ring'.
If you look at the topics, they should be split into smaller clusters like ‘map' ‘nightreign' armor'.
This mega cluster does make sense. All the topics start with ‘elden ring' meaning the word embeddings would place all these keywords in around the same semantic space.
The problem is finding an epsilon number that will cleanly separate these topics.
A mega cluster like this is not usable as a starting base for a SEO optimized page.
How Embedding Bias Distorts Keyword Clusters
When finding related keywords for ‘elden ring', you find a lot of topics starting with that term.
This creates problems when trying to separate them into clusters.
As all these topics share the same prefix, when trying to calculate cosine similarity, they end up really close to each other.
With an incorrect epsilon, this artificial density caused by one dominant entity ‘elden ring' causes mega clusters.
elden ring armor
elden ring arcane
elden ring lore
We need a way to split these mega clusters.
Why Fixed HDBSCAN Fails for Keyword Grouping
HDBSCAN is very sensitive to the epsilon values you give it.
Too small and you get noise and too large and you get mega clusters.
It also changes depending on the seed keyword, so there is unfortunately no one best epsilon for all keywords.
It makes it a challenge to find the sweet spot of noise vs over grouping.
Initially I tried different things to solve this.
- I would manually tweak epsilon, but every time I changed seed keywords the nea epsilon was to big or to small.
- I tried using a strict epsilon upfront, ie 0.10, then do another 2nd pass on the the left over topics labeled as noise (ie 1 topic clusters) with a looser epsilon like 0.20. However this would eventually create a mega cluster. Also same problem as above. The numbers change every time you are working with a different seed topic.
- I even tried removing the initial dominant keyword ‘elden ring' from mega clusters and sending them back to get new embeddings and then reclustering them again. This failed as now topics would end up way to far apart to cluster properly. This also wasted time making extra calls to an external server.
The problem was trying to do everything using 1 or 2 passes.
I found much better results by ‘walking' the epsilon values.
Walking Density: A Smarter Way to Cluster Keywords
Instead of a fixed epsilon, I discovered enumerating through epsilon values starting from 0.05 up to 0.50 and adding 0.01 each time worked much better.
minPoints, I would also iterate starting from 1 to 5.
For each pair of epsilon and minPoint I would keep any clustered topics that was in the range of 3 – 8 topics.
If they fell outside that range I kept it in the topic list and just ran another HDBSCAN on the next set of epsilon values.
The process is something like this:
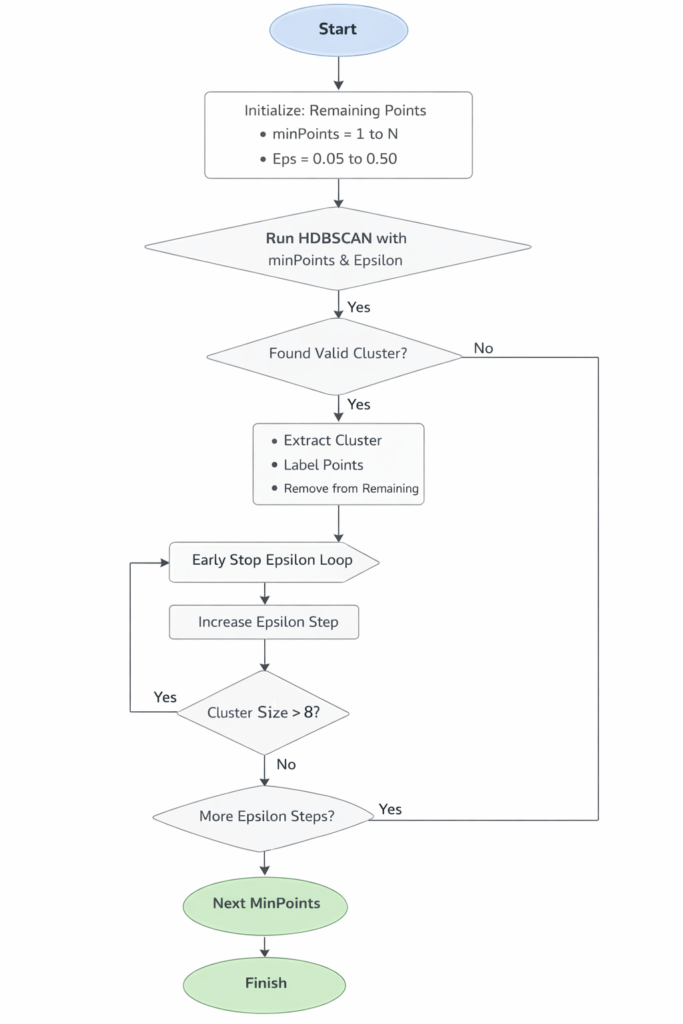
Initially I kept every thing over 3 topics per cluster.
Eventually on high enough epsilon I would still get mega clusters ie epsilon 0.50.
Instead of trying to solve the mega cluster issue now, I ignored it and used the next set of epsilons and minPoints to slowly find other topics.
Eventually after a lot of scanning and removing topics into clusters over time this is the new cluster list.
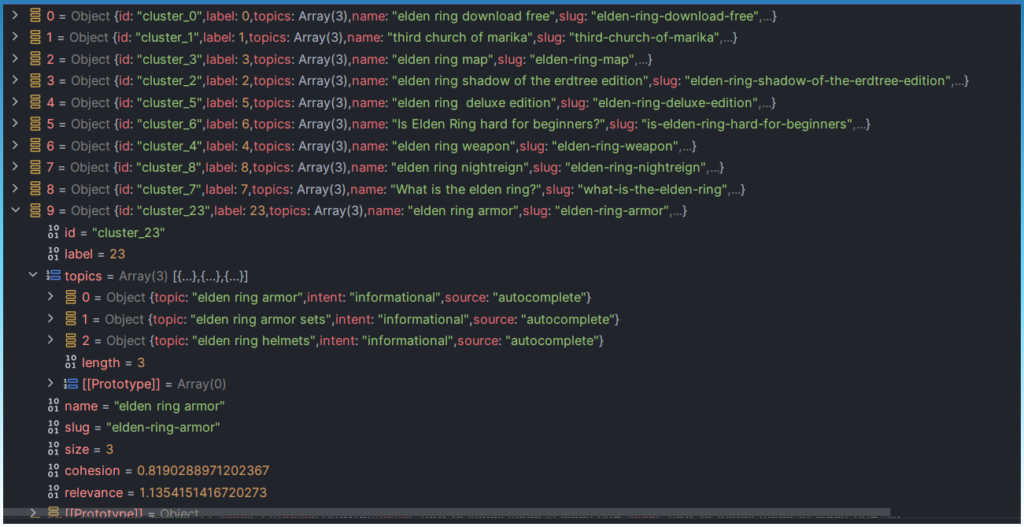
I get a lot of 3-4 topic clusters.
No more mega clusters.
This is exactly what I wanted, a large list of topic clusters.
In fact 115 topics!
Now not all topics are usable, but we can pre-sort that list for the user and let them filter out ones they don't want.
For this list, any clusters of just 1 topic are removed automatically. (Though you can make an argument they might make good 1 page topics).
Now there is loss doing it this way.
Of 500 keywords, you might loose 100-200 of them.
So not every topic you have might be able to neatly fit into a topic cluster.
Why Epsilon Step Size Changes Everything
The biggest decision when deciding to walk the epsilon was to decide on the epsilon step size for HDBSCAN.
A step size of 0.01 was the magic number here.
0.1 was too large a step size.
0.01 was small enough that it could get small 3 word topic clusters, but not too small that it would take too long to scan.
There is a consideration here about resolution verses performance.
In my testing, 500 topics took upwards of 10 secs when using the epsilon walk approach. A perfect trade off to get more clusters.
A small step size allows HDBSCAN to gradually form clusters.
This turns manual tuning into something automatic that scales with any seed keyword.
We let the embeddings decide where they should be clustered.
Engineering Lessons from Building a Clustering Pipeline
Some specific programming implementations.
- Used OpenAI to gather word embeddings. Set max topics to 500 and send all in one batch call.
- Used the smallest embedding model “text-embedding-3-small” as I didn't need the resolution and saved credits calling the smaller model.
- OpenAI sends back normalized embeddings. Save compute by using a simple dot product instead of a proper cosine similarity calculation.
- Removed the embeddings before saving it to file as they are very large number arrays.
What I Learned About Clustering Keywords in Production
Quick overview of the things I learned while testing the implementing a keyword clustering tool.
- Density clustering is very sensitive to epsilon and also the original topic pool
- Consistently re-appearing entities eg ‘elden ring' makes it too easy to over group = mega clusters
- Walking the epsilon takes longer, but you can control cluster sizes very efficiently
- Instead of trying to do manual discrete recluster steps with tweaked parameters it is easier to just walk epsilon and target cluster sizes from the onset
- Intent based pre sorting doesn't work too well as it can create a lot of 1 topic clusters
- I tried reducing dimensions using UMAP before clustering to save compute but actually it was completely un-needed. The actual process of reducing the dimensions took longer than just using the original vectors. For OpenAI, choosing small embedding model is the solution.