
The static, dynamic, search and news and finally RSS scraper tools have been updated with a new ‘unwrap tags' feature.

If you use the static page scraper you can pick content using only the P selector.
When you go to preview the scraped content you get this:

Notice the active links still in the article?
If you try to remove the links using a remove selector you will also remove the content inside the link tag.
The correct way to remove a tag but keep its content is to use an ‘unwrap' operation.
In SCM you can unwrap ‘a' links to remove the link portion but keep the inner text.
Here again with the a unwrap setting.
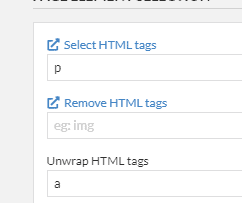
This time when run, the links are removed but the content remains.

If you ever wanted to know how to remove links from a page but keep the inner text in place, you can now do this using an unwrap html tag operation.
This feature has been rolled out where appropriate.
Eg, find it in static, dynamic, search & news and finally in the RSS scraper tools.