

Scraping Google for links so that you can download content is the most effective way to find content using SEO Content Machine.
The default Content Wizard offers it as the only and primary way to select content.
However, sometimes Google scraping may not work due to bans from too much scraping etc.
In cases where you can't get Google scraping to work you have 3 options.
- Use SCM captcha breaker
- Change your IP using VPN
- Switch to a different search engine.
Today I will show you how to switch to using a different search engine.
This can be a good strategy as Google bans automatically lift after about 24 hours.
Custom Search Engines
SCM allows you to find and download content using an internal custom sources list that runs in addition to the Google search.
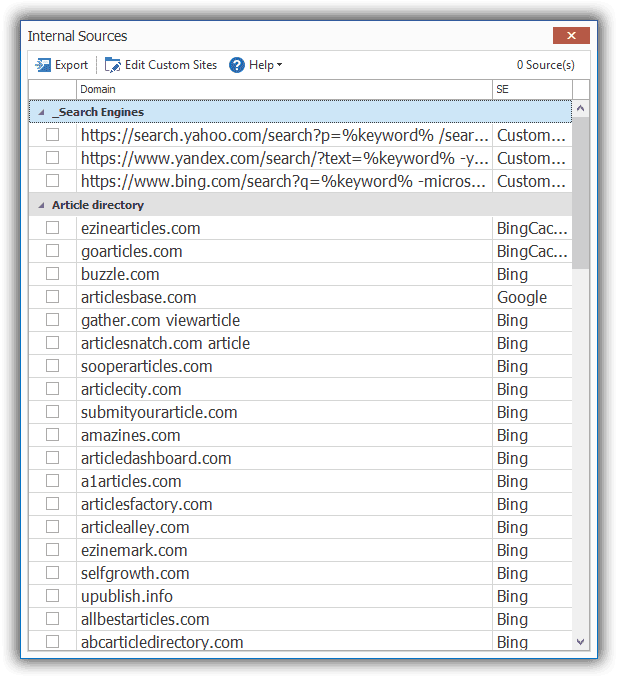
On the first install of SCM, you have a list of article directories in many different languages that you can select to find content.
Additionally, there are 3 search engines that you can use instead of Google.
Yandex, Yahoo and Bing.
To use these search engines do the following.
- Turn off Google by setting the region to [Don't Use Google]
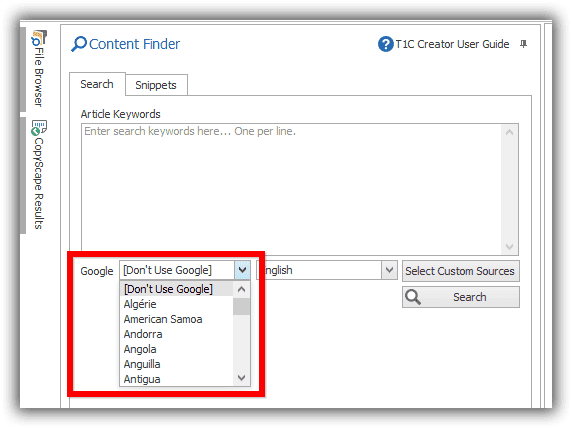
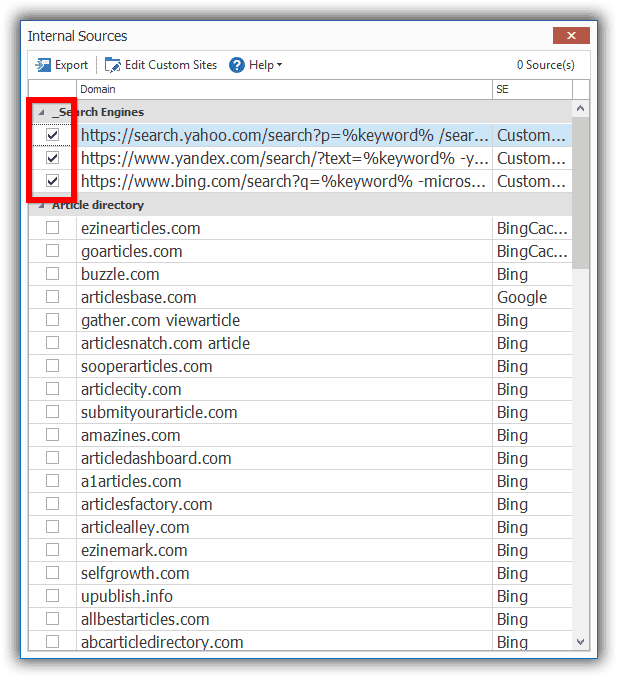
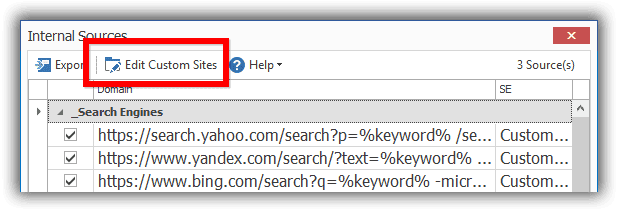
- Click on “Custom Sources” button (NB the process is the same for the article creator). Then check the 3 entries under “_Search Engine”.
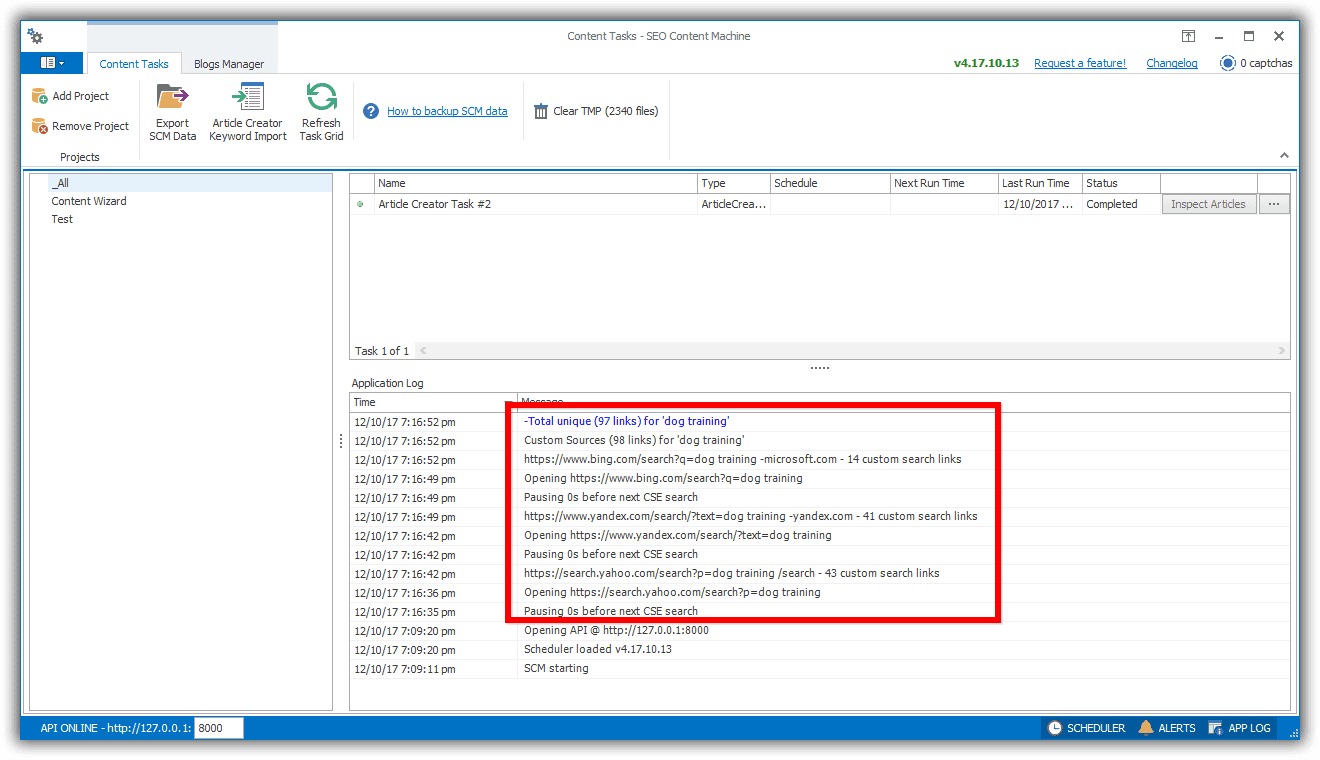
- Verify that SCM is indeed using the 3 search engines by checking the output of the application log.
How to update your custom sources
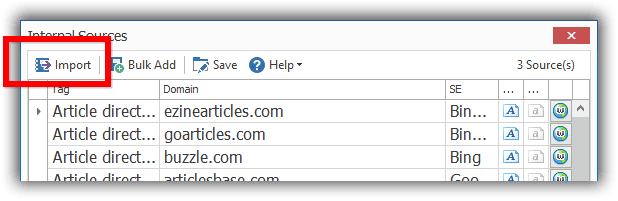
The updated custom sources is only available to new installs of SCM. If you want to add the 3 search engines just download the following file, unzip it and import the XML file.
Download: SEO Content Machine Sources.xml
The SCM custom sources is a very power feature as it allows you to customize your own sources of content. This means you can get access to content that other content generators can't.
Read more about the custom sources here…