

Scraping content from a website can be a difficult thing to do.
If you are not a programmer its even harder.
Using SEO Content Machine, it is possible to scrape content using both Xpath and CSS selectors.
What is Xpath? What is CSS?
Xpath is a way of selecting content from web pages that are written using HTML.
SEO Content Machine allows you to pick out content from any website using Xpath.
Example:
//body//P (xpath)
This xpath will find and extract content that sits in the <body> tag of a web page and then find all the <p> tags under it.
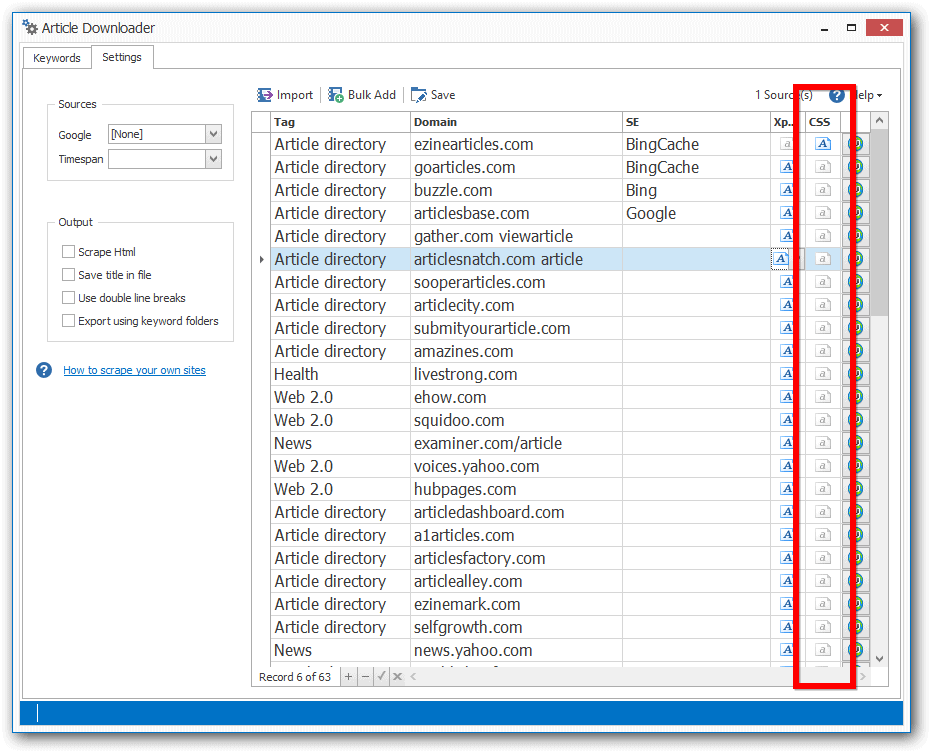
In SEO Content Machine you can see the xpath selectors in the article downloader when you go to the settings tab.
The xpath is used also when running the article creator.
Below is a sample image of what you see in the program.
Xpath is a very obtuse way of selecting content on a web page.
Using CSS gives you a much more readable way to find and scrape content online. Anybody that has ever created a web page will have instantly familiarity with what CSS is and how it works.
You can use CSS selectors to find content on a page just like xpath does.
body p (CSS)
Its the same as the Xpath above but much more readable.
The CSS selection code can be input in the same area as the xpath code is in SEO Content Machine. It appears next door.
The best way to use CSS is to select elements on a web page that you know will have content. You can even select based on what class a web page has applied to a particular element.
Normally this means doing something like “.article-content”.
Xpath or CSS?
Using SEO Content Machine we support both at the same time.
IMPORTANT: SCM will always run the xpath selector first, THEN it will run the CSS selectors.
If you don't need Xpath, just set it blank.
Combine the 2 for some truly advanced content selection possibilities.
For most people CSS is the logical and easy to go to method of selectively telling SCM where to find content.
Although SCM is able to automatically detect content on a page, using Xpath + CSS helps you avoid scraping author names and other meta data you might not be interested in.
How does SCM scrape content?
Here is workflow SCM takes when looking for content:
- SCM downloads the raw HTML of the web page
- It runs the xpath selector first. Typically the default is too just find the //body of the article
- It then runs the optional CSS selector
- It takes the HTML that is left and runs a smart content detection algo to pick out what it thinks is content on the page
- You get back just plain text of the page